
Mit Retrieval Augmented Generation (RAG) Daten verstehen, Wissen vernetzen, Entscheidungen stärken
Generative Sprachmodelle (LLMs) und KI-Agenten gelten aktuell als treibende Kraft der digitalen Transformation. Sie beeindrucken durch ihre Fähigkeit, Sprache zu verstehen, komplexe Texte und Code zu generieren und ganze Arbeitsprozesse zu beschleunigen.
Um zu verstehen, wie diese Technologie funktioniert, lohnt sich ein Blick ins Innere. LLMs lassen sich grob in zwei Teile unterteilen. Auf der linken Seite steht das Modell selbst, das Nutzereingaben (Prompts) aufnimmt und intelligent verarbeitet. Auf der rechten Seite finden sich die Trainingsdaten, auf deren Basis das Modell ursprünglich trainiert wurde.
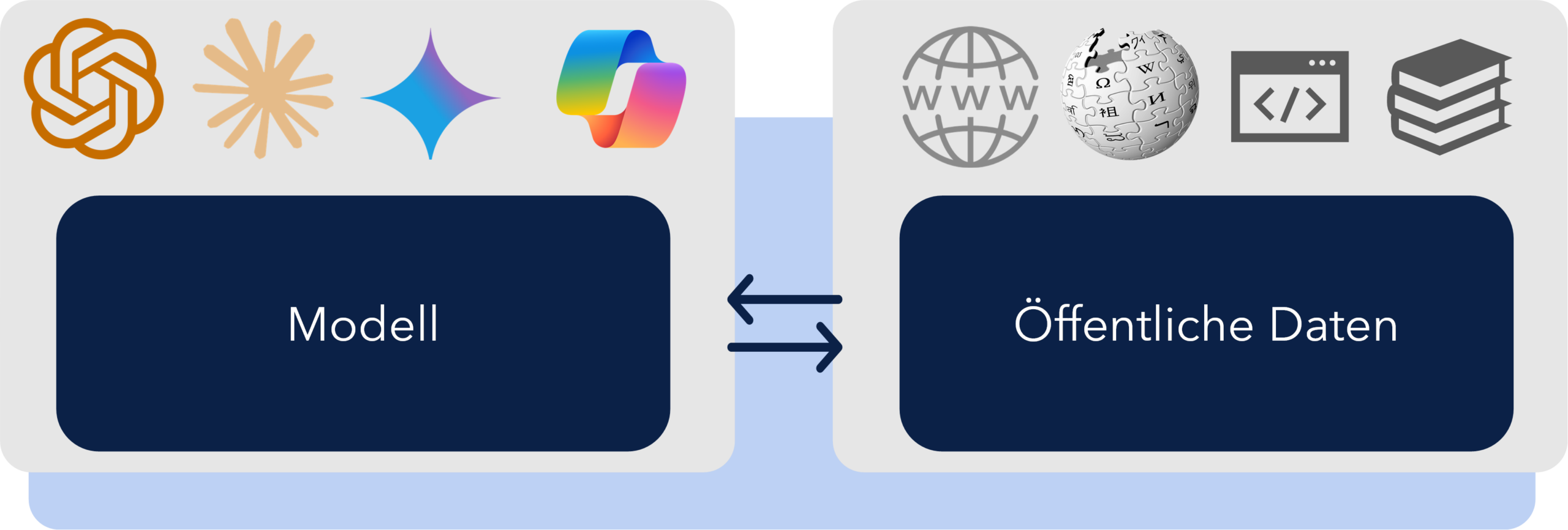
Die großen Anbieter wie OpenAI haben dafür das öffentliche Internet und viele weitere Datenquellen extrahiert, eine gigantische Datenbank (Repository) aufgebaut und darauf die Modelle trainiert. Das führt dazu, dass ein LLM auf bekannte Themen, wie historische Ereignisse, in 99 % der Fälle eine korrekte Antwort liefert, da diese Informationen in den Trainingsdaten enthalten sind. Was allerdings fehlt, ist spezifisches Domänenwissen. Je fremder eine Frage dem Modell ist, desto stärker muss es „reasonen“ und neigt dabei zum Halluzinieren.
Ein Beispiel: Wenn man ChatGPT einen Code-Abschnitt aus einem Java-Programm eines eigenentwickelten IT-Systems der Musterfirma GmbH vorlegt, liefert es eine syntaktisch richtige Antwort, weil es Programmierlogik und Java-Syntax versteht. Doch fachlich bringt diese Antwort nichts, weil das Modell die Musterfirma-Prozesse, internen Richtlinien oder Anforderungen des Fachbereichs nicht kennt. In solchen Fällen ist ein LLM allein wenig hilfreich und manchmal sogar schädlich.
Die Lücke mit Retrieval Augmented Generation schließen
Wie geht man mit diesem Problem um? Die bewährte Lösung heißt Retrieval Augmented Generation (RAG). RAG erweitert den „Daten“-Teil eines LLM gezielt um die eigenen Daten, sei es aus Datenbanken, SharePoint, PDF-Dateien, Code-Repositories oder anderen Wissensquellen. Gleichzeitig wird das Modell so konfiguriert, dass diese Daten bei der Beantwortung von Prompts stets als zentraler Bezugspunkt dienen.
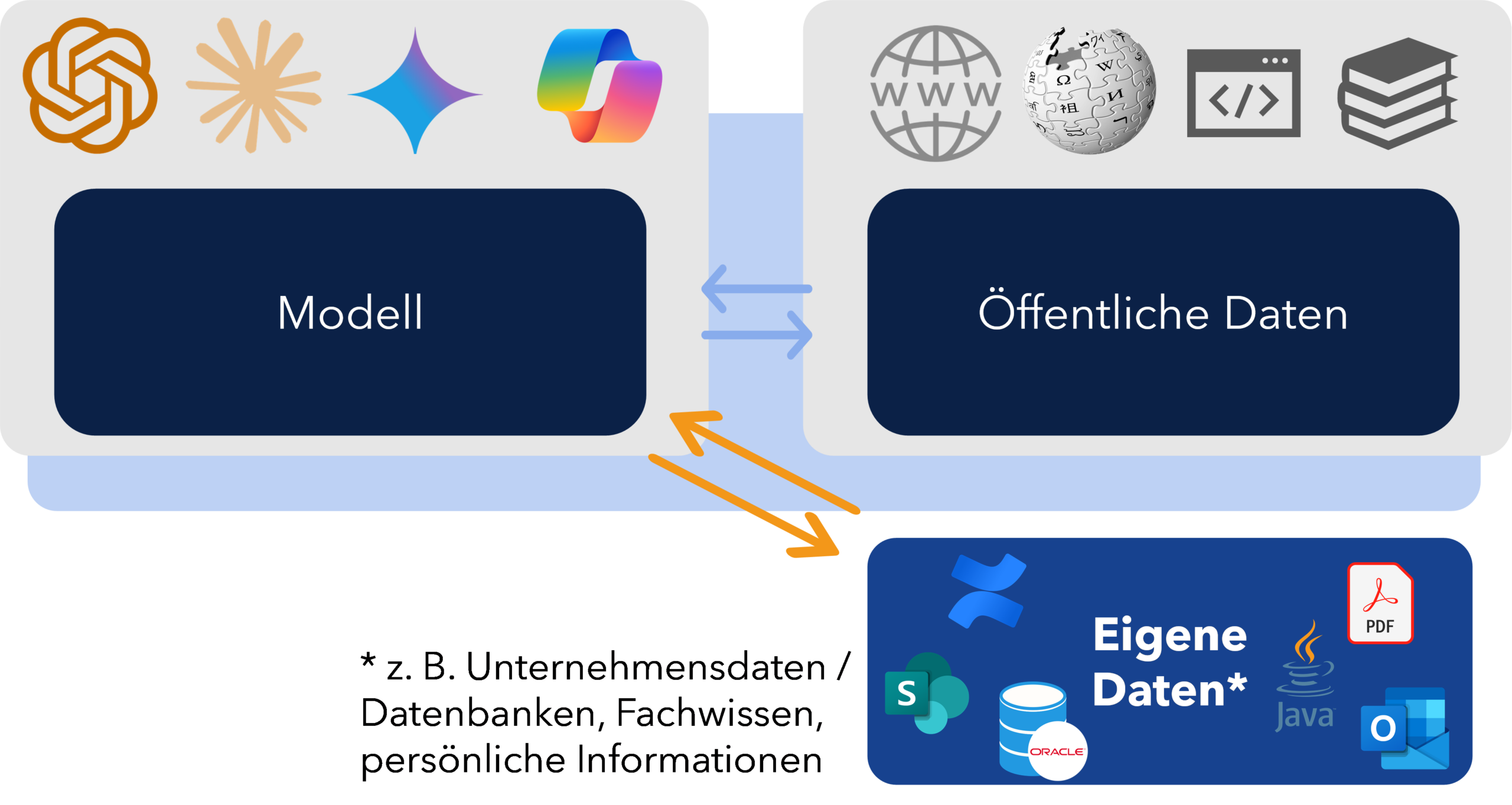
Der Ablauf ist dabei dreistufig:
- Zuerst erfolgt die Modellierung des Wissens in einer Vektordatenbank (Embedding). Kontextual ähnliche semantische Konzepte werden anhand von benachbarten Vektoren mit Hilfe von einem Embedding-Modell repräsentiert.
- Danach der Abruf (Retrieval) von Informationen anhand von Prompts. Das Embedding-Modell analysiert die Prompt-Eingabe, wandelt sie in Vektoren um und identifiziert relevante Informationen aus den angebundenen Referenzmaterialien in der Vektordatenbank.
- Danach folgt die Generierung (Augmented Generation). Die abgerufenen Inhalte werden in die Eingabeaufforderung integriert und liefern dem Modell den notwendigen Kontext. So entsteht eine erweiterte Prompt-Struktur, die dem LLM klar signalisiert, welche Daten es bei der Antwort berücksichtigen soll.
Das Resultat: präzise, aktuelle und domänenspezifische Antworten, die echten Mehrwert für Unternehmen schaffen.
Framework für die Implementierung und Nutzung von RAG
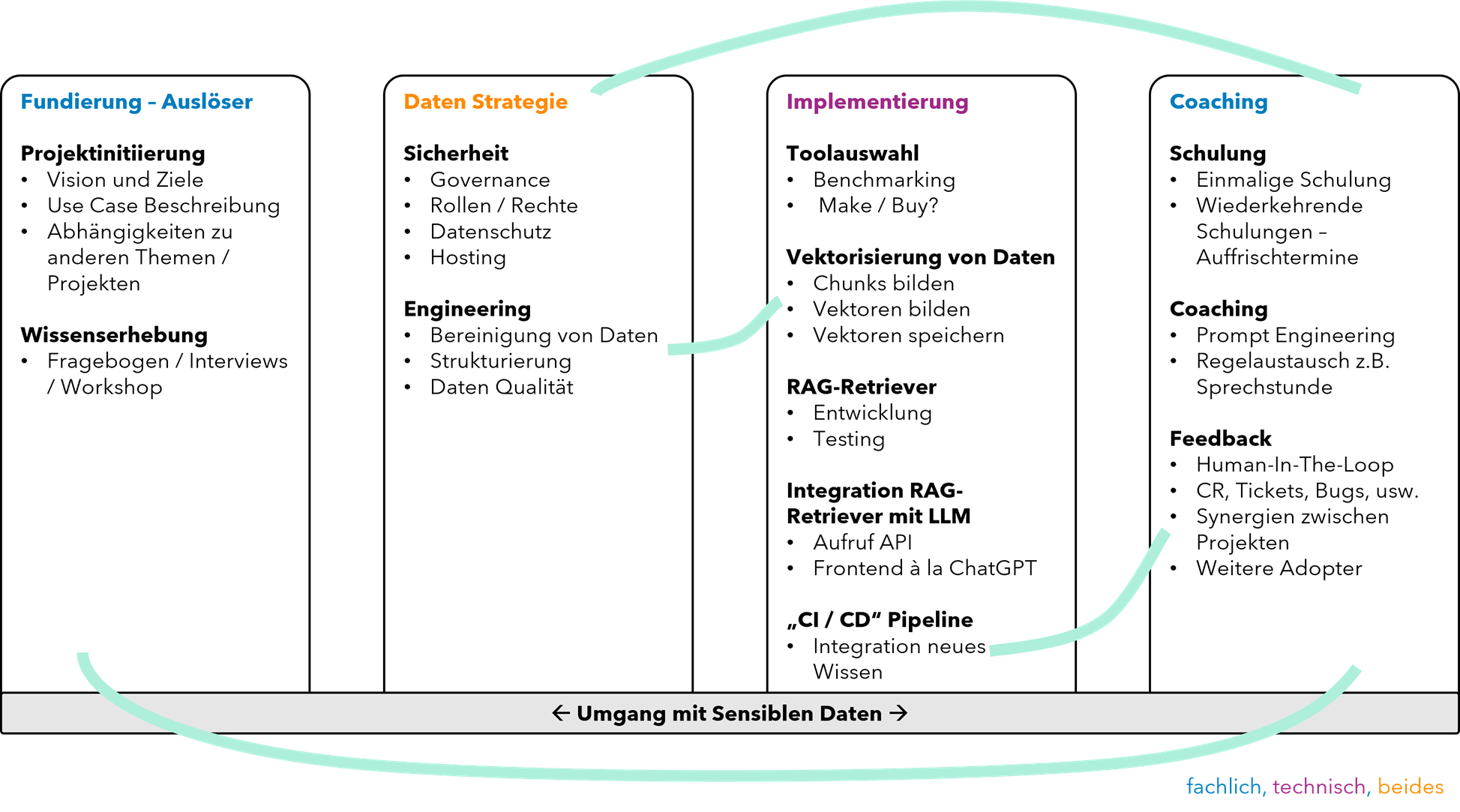
Unser Framework für die Implementierung und Nutzung von RAG ist in vier Hauptbereiche unterteilt, die Zwischenwirkungen und Rückkopplungsschleifen aufweisen. Dieses holistische Framework bettet die RAG-Entwicklung in eine skalierbare und sichere Enterprise-Architektur ein, die den langfristigen Erfolg und die Anpassungsfähigkeit im Unternehmen sicherstellt. Die genauen Aufgaben sind abhängig vom Projektumfang definiert, und können beispielsweise begleitende Arbeiten betreffen (UI, UX, User Journeys / Personas, Change Management, PMO, usw.).
Die erfolgreiche Einführung einer RAG-Lösung basiert auf einer klaren Vision, definierten Use Cases und der Einbindung von Fachwissen über Workshops und Interviews. Eine durchdachte Datenstrategie bildet das Rückgrat. Sie stellt Datenschutz, Governance und Datenqualität sicher und sorgt für übertragbare Ergebnisse. In der Implementierung geht es um die Auswahl geeigneter Tools (Buy vs. Make), die Vektorisierung und Speicherung von Daten, die Integration mit LLMs über APIs sowie eine CI/CD-Pipeline für kontinuierliche Aktualität.
Man ist bei der Umsetzung von RAG äußerst flexibel. Unternehmen können aus verschiedenen Vektordatenbanken wählen, kostenlose oder lizenzierte LLMs per API anbinden und diese lokal oder in der Cloud betreiben. Die Entwicklung erfolgt schnell (vorstellbar innerhalb einer Woche), erfordert kein IT-Großprojekt und lässt sich sowohl als Pro-Code-Lösung für spezifische Anforderungen als auch in Low-/No-Code-Umgebungen wie Microsoft Azure OpenAI oder Azure AI Foundry realisieren.
Nachhaltig nutzbar wird die Lösung durch Coaching, Schulungen und Prompt-Engineering-Trainings, die den Wissenstransfer im Unternehmen sichern. Datenschutz bleibt dabei in allen Phasen zentral, während die modulare Architektur eine flexible Übertragbarkeit auf andere Domänen ermöglicht.
Wirtschaftlicher Mehrwert von RAG
RAG kann Produktivität, Qualität und Geschwindigkeit gleichermaßen steigern. Eine Studie des Singapore General Hospital aus dem Jahr 2024 zeigte, dass sich selbst in einem stark regulierten Bereich wie dem Gesundheitswesen bestimmte Aufgaben durch den Einsatz von RAG von zehn Minuten auf nur 15 bis 20 Sekunden verkürzen lassen bei gleichzeitiger Steigerung der Genauigkeit von 80,1 % auf 91,4 % [arXiv:2402.01733].
Die Integration von RAG in Unternehmensprozesse eröffnet gleich mehrere Dimensionen von Nutzen.
- Antworten werden präziser und relevanter, da sie auf validierten Wissensquellen beruhen.
- Neue Informationen sind sofort verfügbar, ohne dass das Modell von Grund auf neu trainiert werden muss.
- Gleichzeitig behalten Unternehmen die volle Kontrolle über Datenzugriffe, Compliance und Nachvollziehbarkeit. Das ist ein entscheidender Faktor, um regulatorische Risiken zu minimieren.
Darüber hinaus macht RAG den Schritt von Pilotprojekten zu produktiven Anwendungen möglich. Wissen wird effizienter zugänglich, Mitarbeitende werden entlastet und Fachbereiche erhalten schneller die Informationen, die sie wirklich brauchen.
Erfolgsfaktoren für eine erfolgreiche Einführung von RAG: Informationssicherheit, Datenschutz und Vertrauenswürdigkeit
So mächtig RAG ist, verlangt seine Einführung mehr als reine Technologie. Die Qualität der Ergebnisse hängt maßgeblich von der Datenbasis ab. Nur kuratierte, strukturierte Inhalte ermöglichen wirklich belastbare Antworten. Parallel dazu ist Change Management unverzichtbar: Mitarbeitende müssen lernen, mit den neuen Werkzeugen zu arbeiten und präzise Fragen zu stellen.
Ebenso entscheidend sind klare Regeln für Datenzugriff, Datenschutz und Compliance. Ohne Governance droht RAG zum Risiko, statt zum Nutzen zu werden. Schließlich empfiehlt sich ein iteratives Vorgehen: PoCs, die in enger Abstimmung mit den Fachbereichen getestet und anschließend skaliert werden, sind der Schlüssel zum Erfolg.
Die Einführung von RAG bedeutet immer auch, Fragen der Informationssicherheit und des Datenschutzes klar zu adressieren. Abhängig von der gewählten Lösung ist sicherzustellen, dass keine schützenswerten oder sensiblen Daten unkontrolliert an öffentliche KI-Modelle weitergegeben werden. Unternehmen müssen den Grad der Sensibilität ihrer Daten im Vorfeld einschätzen und entsprechende Schutzmaßnahmen definieren, von der Datenklassifizierung bis zur technischen Absicherung.
Darüber hinaus spielt die Vermeidung von Verzerrungen (Bias) und Diskriminierung eine wichtige Rolle. Da LLMs aus bestehenden Daten lernen, spiegeln sie auch deren Verzerrungen wider. Je nach Einsatzgebiet müssen Mechanismen etabliert werden, die solche Risiken erkennen und minimieren.
Auch die Ergebnisqualität hängt direkt von der Datenbasis ab: „Garbage in, garbage out“ gilt mehr denn je. Nur wer hochwertige, valide Inhalte einbindet, kann belastbare Resultate erwarten. Gleichzeitig ist zu beobachten, dass sich die Qualität der Ergebnisse durch die rasante Weiterentwicklung von Modellen und RAG-Technologien spürbar verbessert. Dennoch bleibt es notwendig, gerade bei geschäftskritischen Anwendungen, die Resultate kontinuierlich zu bewerten.
Beim Logging wird festgehalten, was die KI als Eingabe erhalten hat, welche internen Schritte sie durchgeführt hat und welche Antwort sie gegeben hat. Beispiel: Ein Chatbot empfiehlt im Kundenservice eine Rückerstattung. Im Log ist dann ersichtlich, welche Frage gestellt wurde, welche Kundendaten berücksichtigt wurden (z. B. Bestellnummer, Rückgabefrist) und wie die KI zu ihrer Empfehlung gekommen ist. So kann später geprüft werden, ob die Entscheidung auf korrekten und vollständigen Informationen beruhte. Explainability bedeutet, dass die KI ihre Entscheidungen begründet. Beispiel: Ein Recruiting-Tool zeigt, dass ein Bewerber ausgewählt wurde, weil bestimmte Schlüsselbegriffe im Lebenslauf vorkamen, etwa ‚Python‘ oder ‚Projektmanagement‘. So wird klar, dass die Auswahl nachvollziehbar ist und nicht auf Vorurteilen basiert.
Fazit: RAG macht KI geschäftstauglich
Generative KI liefert beeindruckende Ergebnisse, aber ohne Kontext bleiben sie oft unzuverlässig. Erst durch RAG entfaltet sie ihr volles Potenzial im Unternehmenskontext. Mit der Anbindung firmeneigener Datenquellen entstehen präzise, aktuelle und vertrauenswürdige Antworten, die sich unmittelbar in Wertschöpfung übersetzen lassen.
RAG ist damit kein bloßes Add-on, sondern ein strategischer Baustein der digitalen Transformation. Unternehmen, die diese Technologie frühzeitig einsetzen, sichern sich nicht nur Effizienzgewinne, sondern auch einen entscheidenden Wettbewerbsvorteil.
In den kommenden Impulsen erhalten Sie einen praxisnahen Einblick, wie unsere RAG-Lösungen bereits in verschiedenen Industrieprojekten erfolgreich umgesetzt wurden. Sie lernen, welche Herausforderungen dabei gemeistert wurden, welche messbaren Vorteile erzielt werden konnten und wie sich RAG als Teil einer nachhaltigen Digitalstrategie bewährt hat.
Lassen Sie sich inspirieren und entdecken Sie, wie Ihr Unternehmen von innovativen KI-Anwendungen profitieren kann. Sprechen Sie uns gerne direkt an, wenn Sie konkrete Fragestellungen oder Interesse an einem Proof-of-Concept haben. Wir begleiten Sie von der ersten Idee bis zur erfolgreichen Implementierung und freuen uns auf den gemeinsamen Austausch. Kontaktieren Sie uns gerne unverbindlich für ein Gespräch!
 Daten verstehen, Wissen vernetzen, Entscheidungen stärken")






